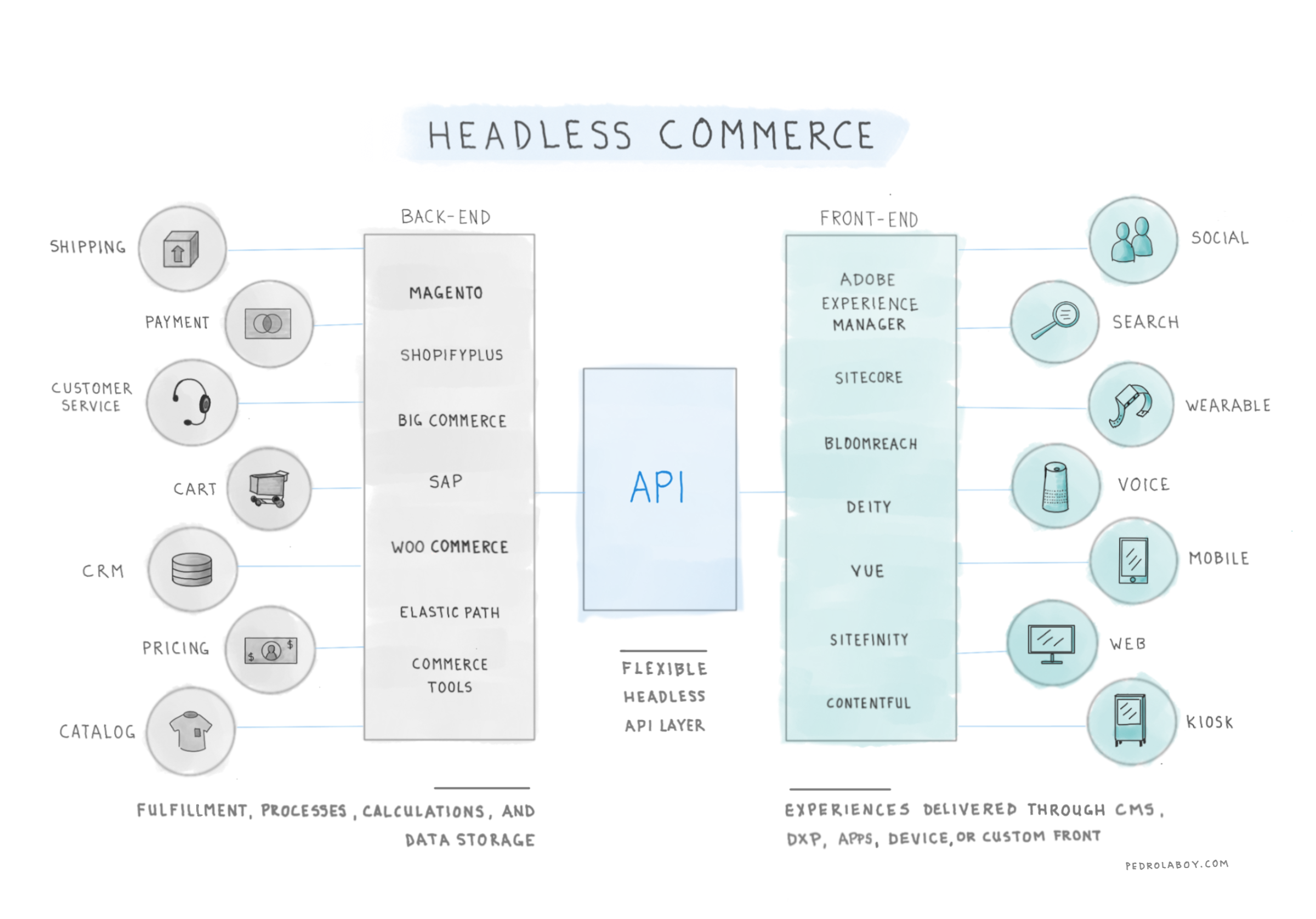
Every HR department and talent acquisition agency knows that in today’s tight labor market it is extremely difficult to find the talent that meets the organization’s business needs. In other words, the way we go about matching talent to job openings is still pretty much in the dark ages. For employers, the process is slow, expensive and labor intensive. For applicants, it is often difficult to find open positions that are a fit.
However, today we can leverage artificial intelligence (AI) and machine learning (ML) to transform the way we match talent to employers. An AI/ML solution could be built using multiple technologies but using the Google or Amazon Cloud offers cost savings, scalability and speed that few can match.
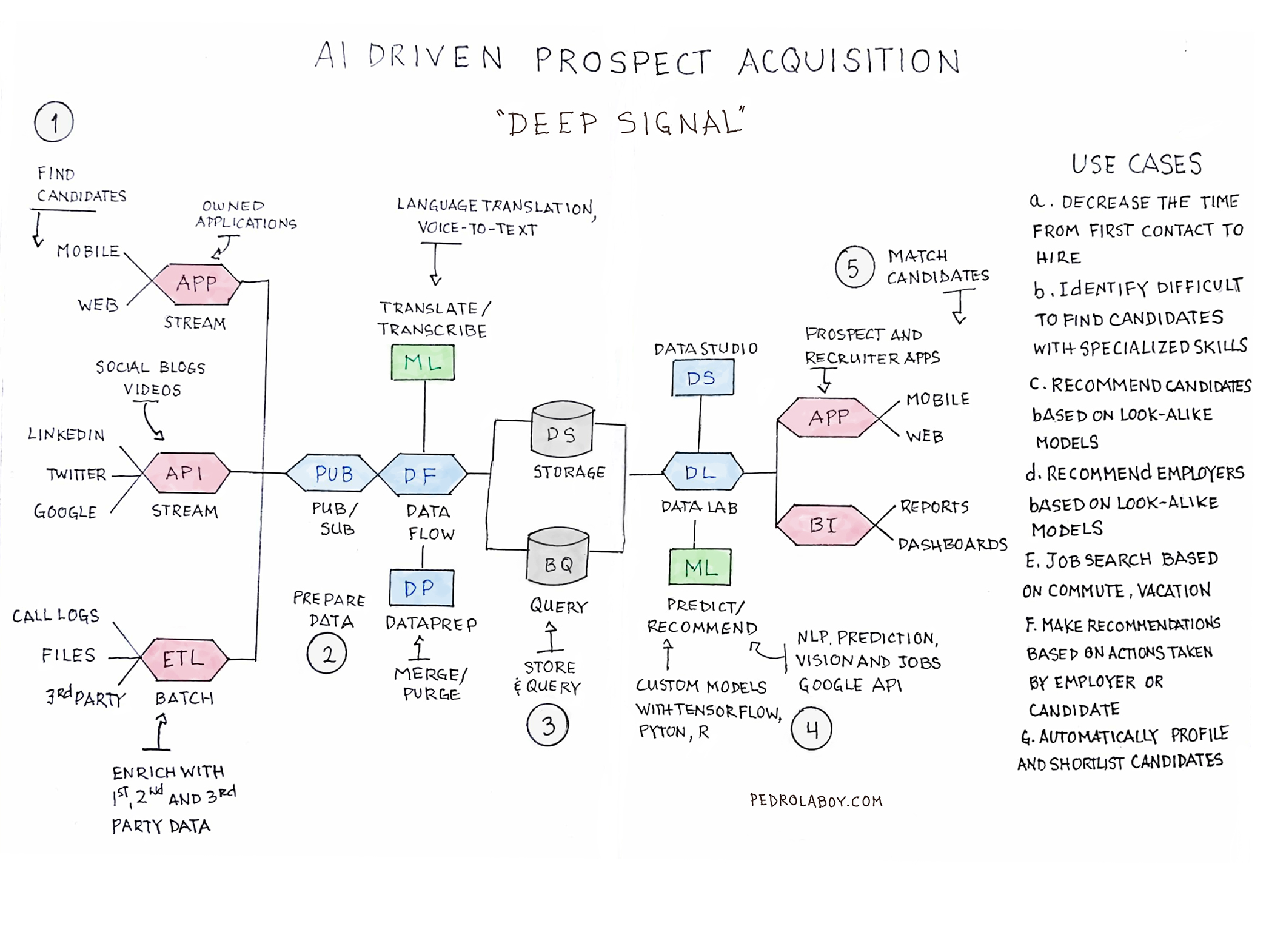
The above is a sketched architecture of what the platform could look like using the Google Cloud. I will call this solution Deep Signal.
Sample Use Cases
So, what could you do with Deep Signal? Here are a small sample of use cases:
1. Candidate Sourcing and Placement – Source candidates faster and more accurately (decrease the time from first contact to placement)
2. Source Specialty Candidates – Identify difficult to find candidates with specialized skills
3. Candidate Recommendation Engine – Recommend candidates based on look-a-like modeling (if you liked this resume, you will also like these other resumes)
4. Employer recommendations Engine – Recommend employers based on look-a-like modeling (if you are interested in this employer, you will also like these other employers)
5. Smart Search – Job search based on non-traditional features (commute time, vacation, etc.)
6. Next Best Action – Make recommendations based on actions taken by employer or candidate
7. Identify Prospective Clients – Identify prospective clients based on existing candidate database (this prospective employer will be interested in these candidates)
Technical Requirements
There are two things that will be needed in order to build a AI driven platform. The first one is data. Without extensive categorical and historical data, you cannot build accurate machine learning models. The second thing we will need is computing power. Without enough computing power, it could take weeks or months to run our models. Both Amazon and Google offer solutions with more than enough computing power to handle anything you throw at them.
Final Thought
Transforming into a data-driven business model based on machine learning and artificial intelligence requires more than deploying new technologies. It often requires cultural and organizational shifts as the business adapts to the realignment of data, people, process and technology.
As always, questions and thoughts are welcome. If you give me a use case and I will think of ways ML/AI could be used.