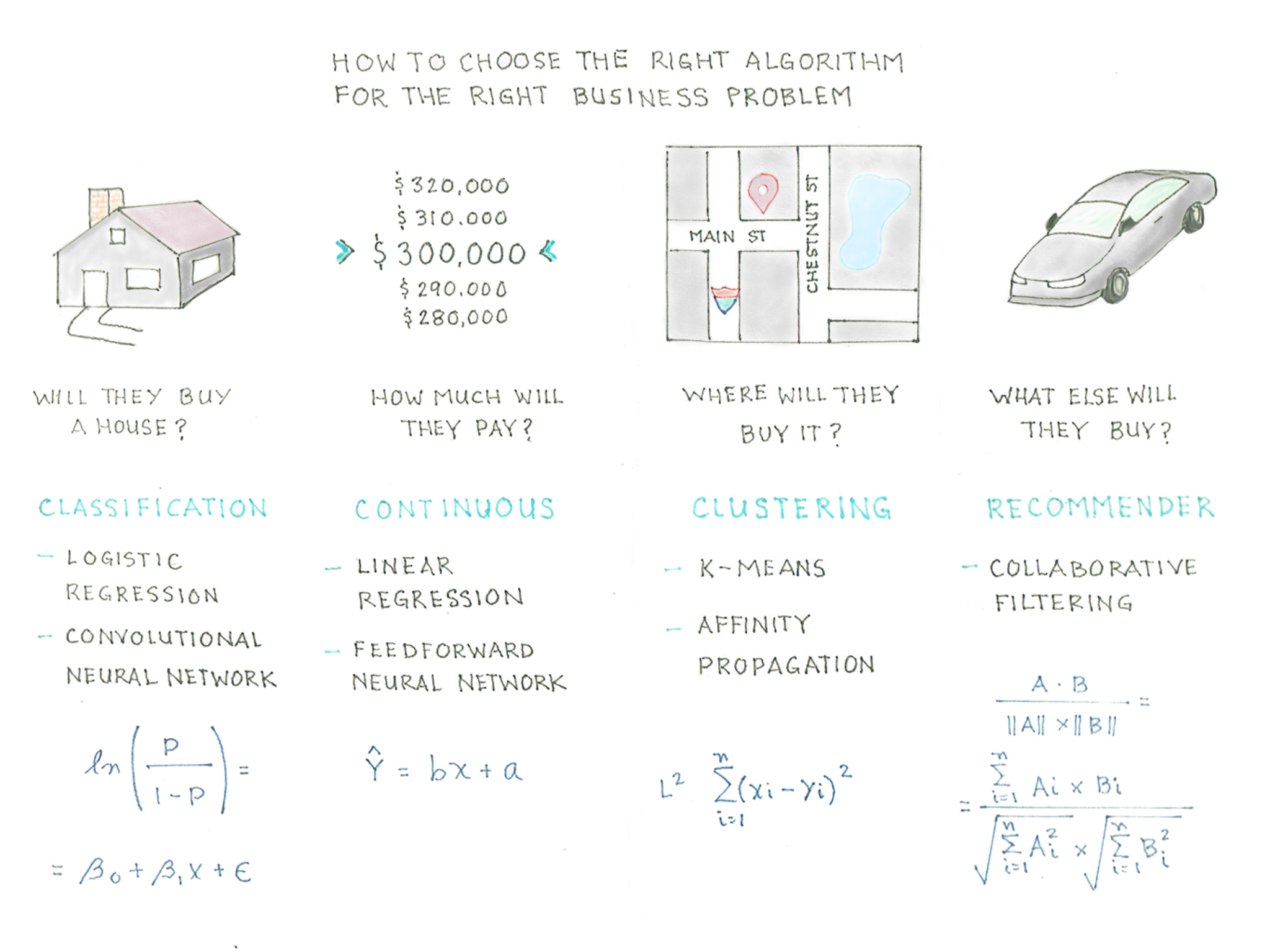
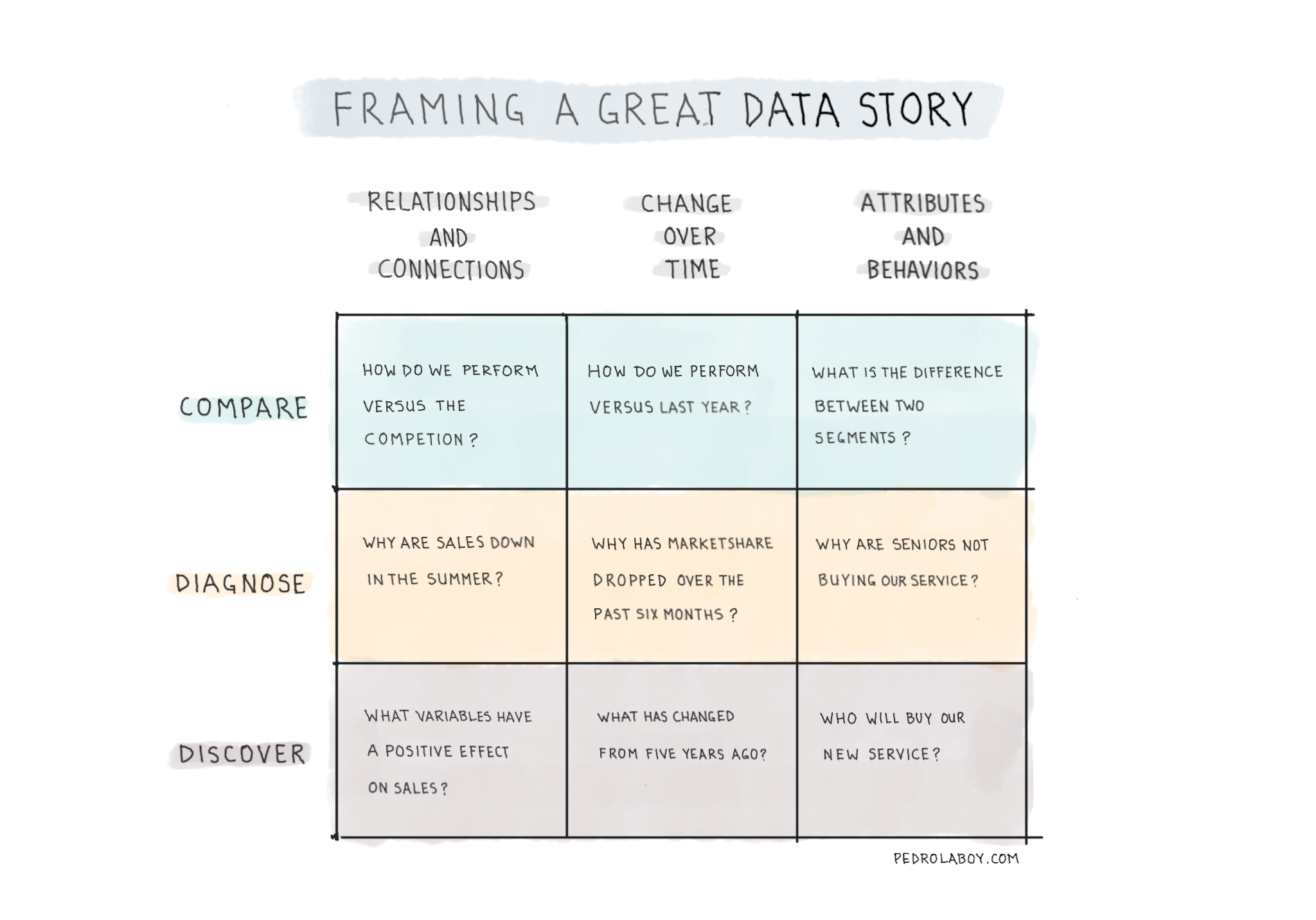
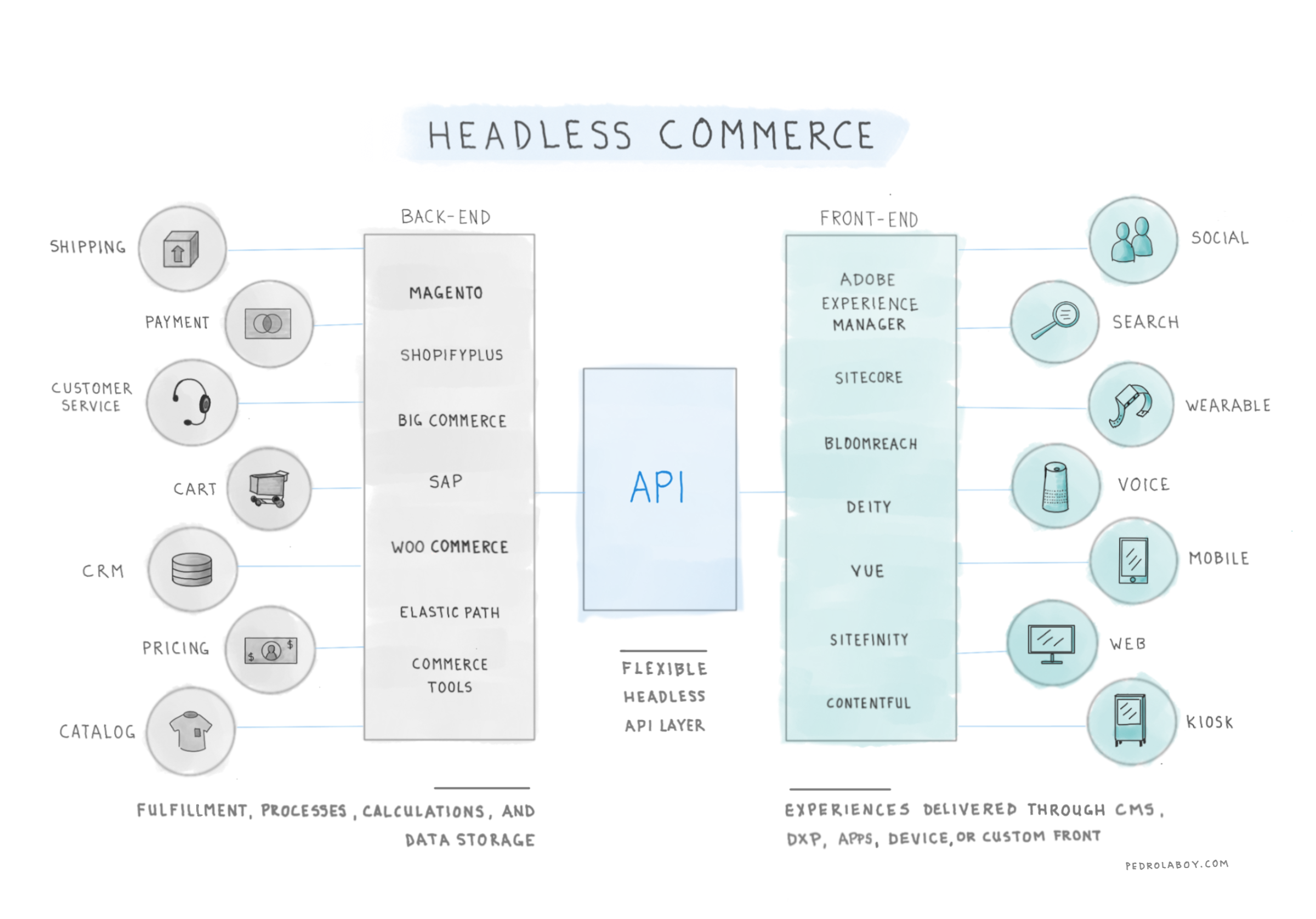
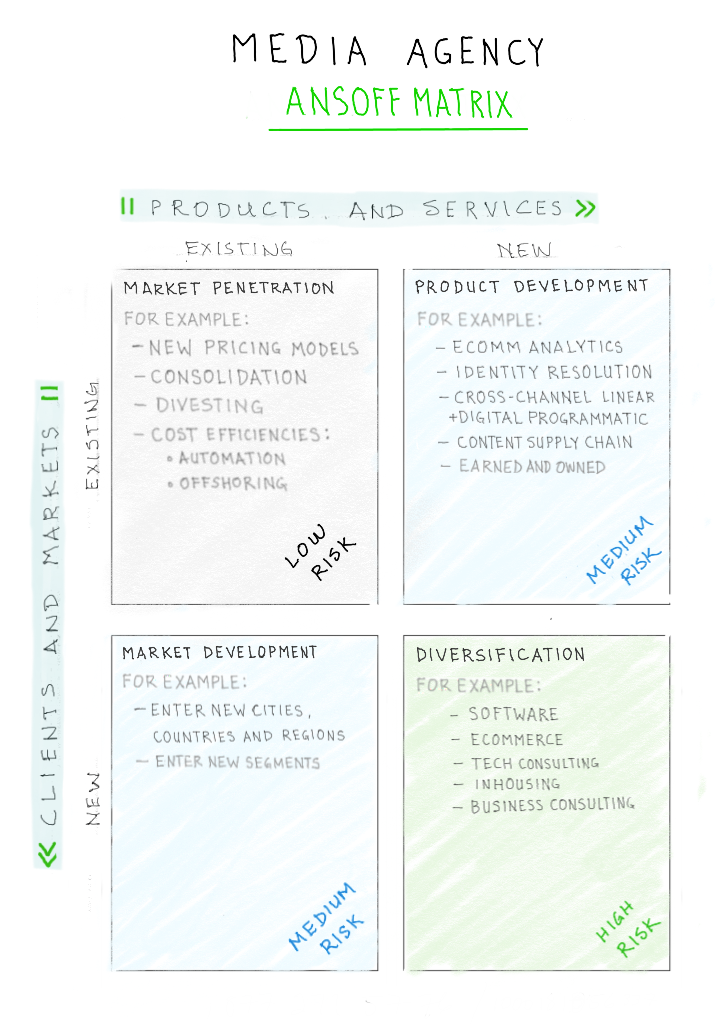
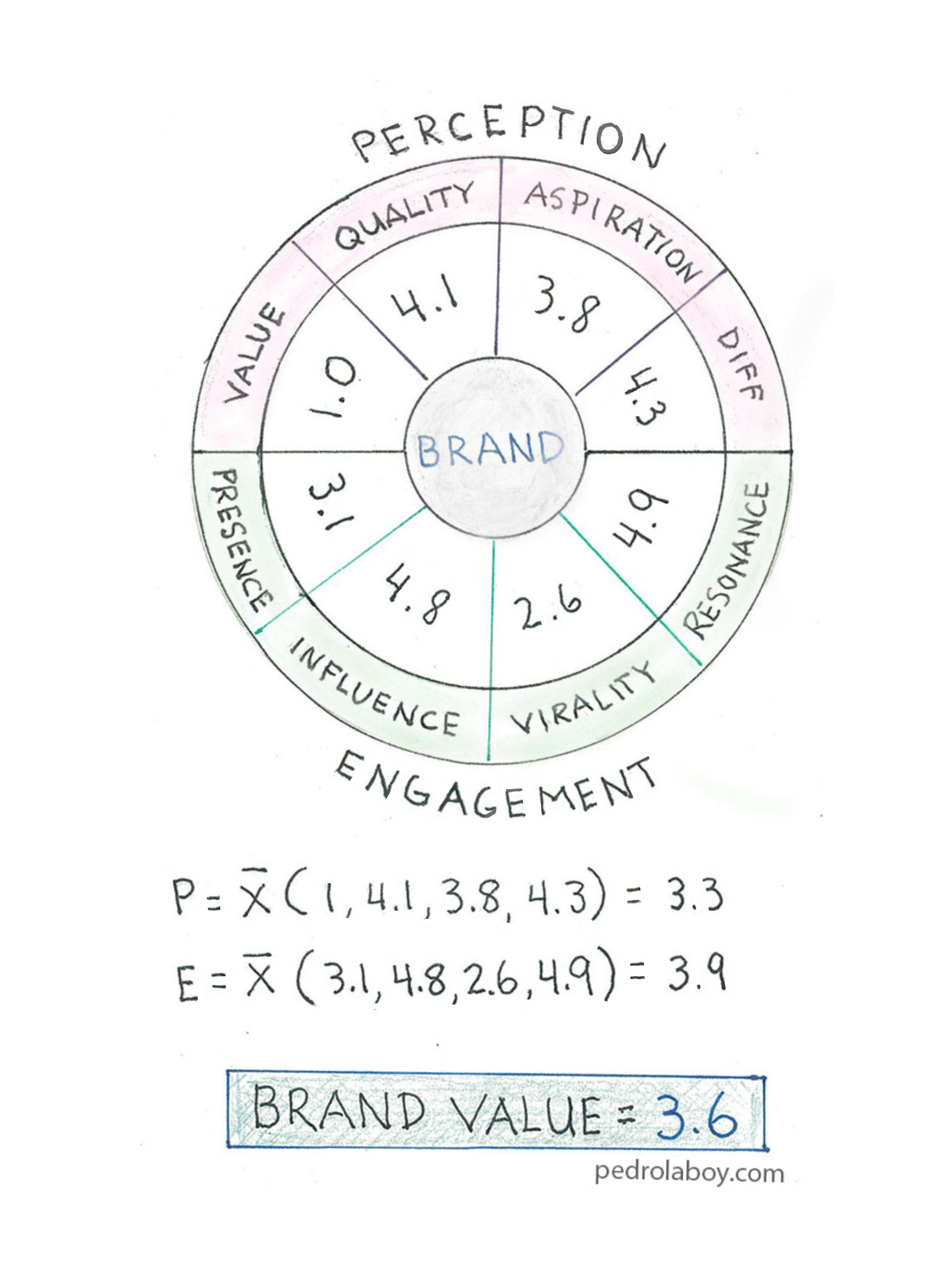
There are many types of marketing measures that can be applied to a customer’s purchase and experience journey. However, what’s important is that these measures can both determine the effectiveness of specific marketing campaigns and predict the likelihood that a customer will move from one stage of the journey to the next.
Here is a sample of some of methodologies and/or measures that can be used in the different stages of the journey:
NEED
Market Analysis – Determine market needs
Experience Analysis – Determine prospective customer needs and/or opportunities to improve customer experience
RESEARCH
Awareness – Determine level of brand and product awareness
Segmentation – Segment customers to the smallest groupings feasible
Addressability – Level of addressability for each segment
SELECT
Media Mix Modeling – What are the optimal media channels we should use to reach our audiences
Multi Touch Attribution – How are channels performing for given audiences and campaigns
Brand Preference – What is the consumer brand preference within our category
Qualified Leads – Are we getting the desired level of marketing and sales qualified leads
PURCHASE
Propensity to Purchase – What is the likelihood that our audience will purchase our products
Cart Abandonment – Are prospective customers dropping off before completing a purchase
Conversation Rate – What is the conversation rate for our desired actions
Time to Purchase – What is the timeframe from first touch to purchase
Up-Sell / Cross-Sell – Are we able to up-sell and/or cross-sell to our customers
Share of Wallet – What is the share of wallet
Basket Size – How much are our customers spending per purchase
RECEIVE
Propensity to Return – Are our products being returned at unacceptable rates
EXPERIENCE
Sentiment Analysis – How do customers feel about our brands, products, services and delivered experiences
Customer Effort Score – What is the level of effort required by a customer to resolve an issue
Customer Satisfaction – What is the level of customer satisfaction
Respond and Resolution Time – how much time does it take to respond to and resolve an issue
RECOMMEND
Net Promoter Score – What are our customer’s willingness to recommend
Brand Mentions – Is our brand being mentioned positively and at the right level
Revenue Referrals – How much revenue are we generating from referrals
REPURCHASE
Repurchase Rate – Are our customers returning
Frequency – What is the time between purchases within a specific time period
Recency – How many days since the last purchase
Redemption Rate – What are the number of rewards that are being redeemed
Customer Lifetime Value – What is the estimated lifetime value of our targeted segments
OVER TO YOU!
As always, your thoughts and comments are welcomed. What else could we measure at each stage of the journey? What is your approach?