Home
Work
AI Journal
About
Contact
Home
Work
AI Journal
About
Contact
© 2025 Created by
Pedro Laboy
Algorithms
3 articles
Home
Algorithms
#AI Agents
#Algorithms
#Artifical Intelligence
#digital transformation
#predictive analytics
#RAG
#strategy
#Technology
6 mins to read
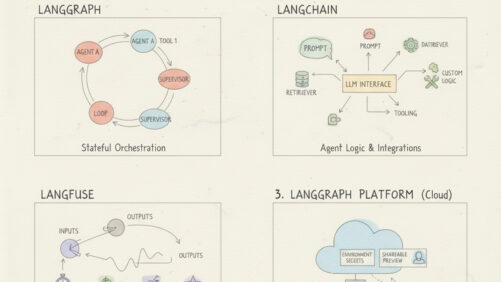
Building an AI Agent Framework with the “Lang” Stack
Pedro Laboy
June 7, 2025
Read More
#Algorithms
#Analytics
#Artifical Intelligence
#Data Science
#Machine Learning
2 mins to read
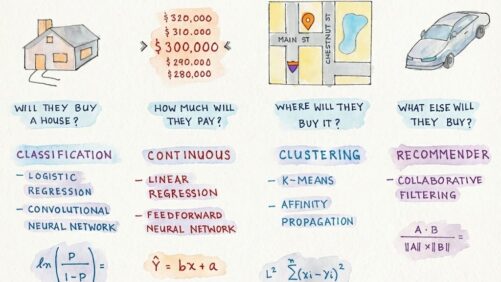
Notebook Thoughts: Choosing the Right AI Algorithm for the Right Problem
Pedro Laboy
October 15, 2019
Read More
#Algorithms
#Analytics
#brand health
#Data Science
#Machine Learning
#sentiment
#social analytics
#social media
2 mins to read
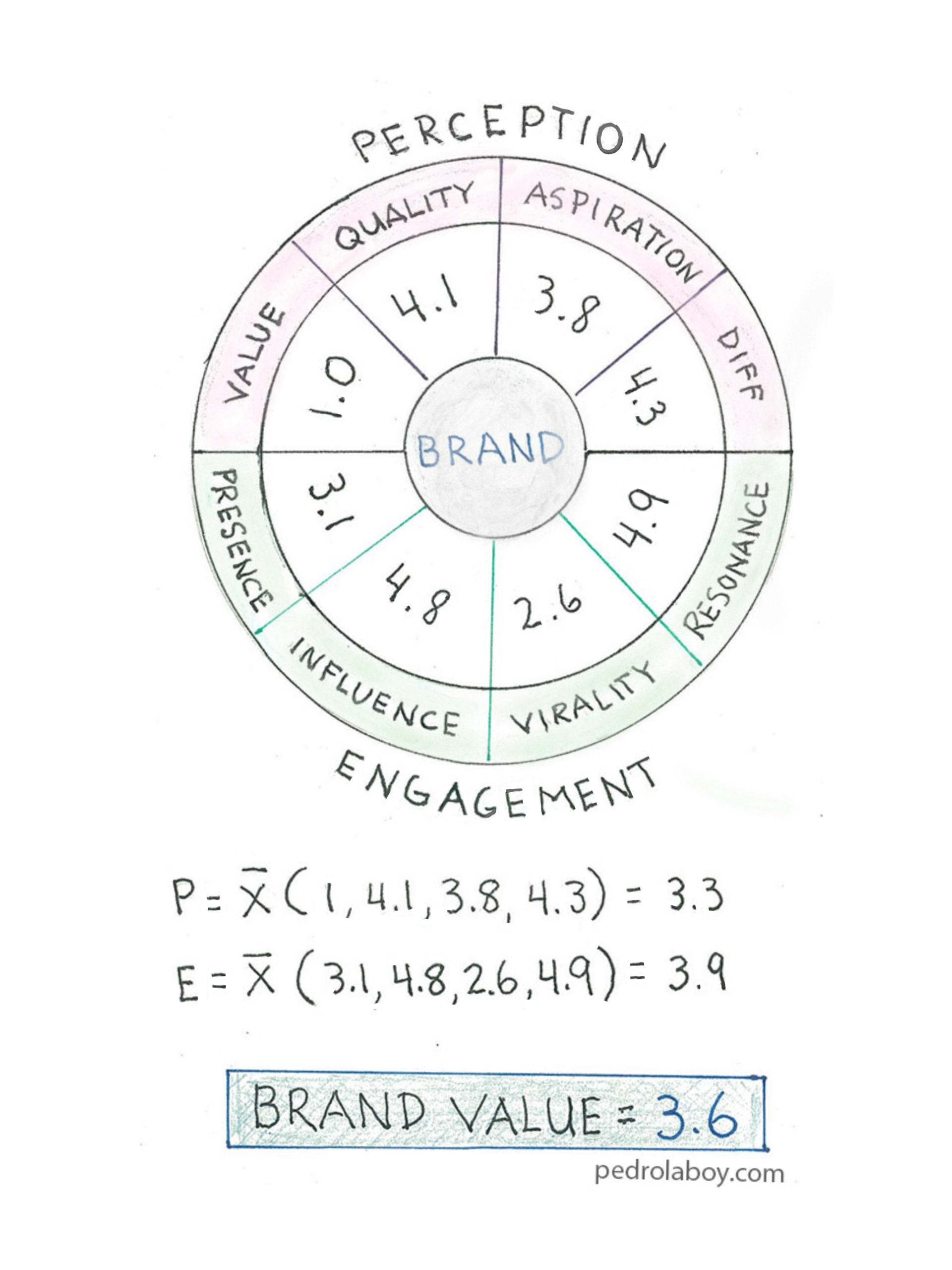
Notebook Thoughts: Using Social Media to Measure Brand Health
Pedro Laboy
May 26, 2019
Read More