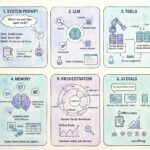
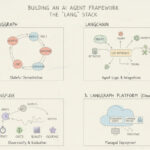
As of September 2025, the “Lang” ecosystem, centered on LangGraph (orchestration), LangChain (LLM + tools), and Langfuse (observability/evals), has matured into a pragmatic foundation for building reliable, multi-agent systems. LangGraph provides explicit, stateful control flow, LangChain standardizes model/tool abstractions and I/O schemas, and Langfuse gives you rigorous tracing, evaluation, and experiment management. Together, they let you move from demos to dependable, monitored, continuously-improving agent workflows that your stakeholders can trust.

🔹 LangGraph→ Orchestrates the agent(s) as a stateful graph (nodes = agents/tools; edges = control flow). Supports single-agent and multi-agent patterns, supervisors, loops, handoffs, streaming, and persistence.
🔹 LangChain→ Provides LLM interfaces, tool/function-calling agents, prompt templates, retrievers/stores, and broad integrations. Use it to implement each node’s “agent logic.”
🔹 Langfuse→ End-to-end observability, tracing, evaluation, and experiment management (inputs/outputs, tool calls, latencies, costs). Use it to debug, compare prompts/models, and score quality before/after launch.
🔹 LangGraph Platform (Cloud) → Managed deployment for your graphs with environment secrets and shareable previews for collaboration.
🔹 Graph state & handoffs.Agents pass messages and structured state across nodes, a supervisor routes the next step or stops.
🔹 Tool-calling vs ReAct.Prefer tool/function calling for reliability (structured schemas and strong provider support), use ReAct only when you truly need free-form chain-of-thought planning.
🔹 Observability first. Instrument every call from day one, traces, spans, retries, metrics, costs, and evals, to shorten iteration cycles and prevent regressions.3) Step-by-step build plan
1️⃣ Create a mono-repo (e.g., apps/agent-api, packages/common) with Python or JS runtime for LangGraph nodes and LangChain tools.
2️⃣ Choose LLMs (OpenAI/Anthropic/Gemini, etc.) and a vector store if you need RAG.
3️⃣ Add deps: langgraph, langchain, provider SDK(s), langfuse, datastore clients.
4️⃣ Build a minimal single-agent graph that echoes input to confirm wiring, then expand.
🔹 Nodes:one capability per node (Planner, Researcher, Tool-Executor, Writer, Reviewer).
🔹 Supervisor:routes based on “who acts next” (LLM-driven or fixed logic).
🔹 State:define a typed model with messages, scratchpad, plan, artifacts, and metadata (latency budgets, cost ceilings).
🔹 Transitions: directed edges (e.g., Planner → Researcher → Tool-Executor → Writer → Reviewer → END) with loops and guards.
🔹 Wrap each external action (search, DB query, GA4, CRM, file I/O) as a LangChain Toolwith JSON schemas.
🔹 Use LangChain’s tool-calling agent helpers so the model reliably selects and executes tools and returns structured outputs.
Minimal Python sketch (agent node)
from langchain_openai import ChatOpenAI from langchain_core.tools import tool from langchain.agents import create_tool_calling_agent from langchain_core.prompts import ChatPromptTemplate @tool def get_kpis(account_id: str) -> dict: """Fetch KPIs for an account_id from analytics API.""" # ... fetch and return dict ... llm = ChatOpenAI(model="gpt-4o-mini") # example tools = [get_kpis] prompt = ChatPromptTemplate.from_messages([ ("system", "You are a precise analyst. Use tools if needed."), ("human", "{input}") ]) agent = create_tool_calling_agent(llm=llm, tools=tools, prompt=prompt)
🔹 Each node invokes one agent/tool and returns updated state(messages + artifacts).
🔹 Add a supervisor nodethat inspects state and decides the next node (or END).
🔹 Enable streaming and checkpoint persistence as needed.
🔹 Initialize Langfuse early (keys/host).
🔹 Wrap LLM/tool calls in spans (LangChain integration can emit spans automatically).
🔹 Create Experiments with Datasets and Evaluation Methods (exact match, rubric scores, model-graded) to compare prompts/models/guardrails before shipping.
Minimal Python sketch (Langfuse)
from langfuse import Langfuse lf = Langfuse(public_key="...", secret_key="...", host="https://cloud.langfuse.com") trace = lf.trace(name="run-graph", input=state) span = trace.span(name="planner-call") # attach llm input/output, tool results, costs, timings span.end() trace.update(output=state)
🔹 Retries/timeouts at the tool layer, circuit breakers on expensive paths, max turnsin the supervisor.
🔹 Schema validation(Pydantic) on tool outputs, add output validators before mutating state.
🔹 Human-in-the-loop review node for sensitive tasks and approvals.
🔹 Connect GitHub, set environment secrets (OPENAI_API_KEY, etc.), configure build targets, and publish.
🔹 Share via Studio for stakeholders or gate behind workspace keys.
🔹 Use for linear tasks where you need tool access + memory.
🔹 Implement a single tool-calling agent as the active node, the graph manages lifecycle/state.
🔹 A Supervisordecides which specialist acts next (Planner, Researcher, Coder, Reviewer).
🔹 Pass graph state via handoffs, each node updates state then yields control. Ideal when responsibilities are clear.
🔹 Planner decomposes goals, sub-agents work in parallel, a Reducer merges results.
🔹 Useful for synthesis and latency reduction (parallel edges).
🔹 Prefer tool/function callingover raw ReAct for stability, schema control, and vendor portability.
🔹 Keep nodes small & explicit.One responsibility per node, pass only the state you need.
🔹 Budget control in state.Track max turns, max cost, and latency targets, have the supervisor enforce them.
🔹 Instrument experiments.Use Langfuse Experiments to compare prompt versions, models, top-k, or toolsets on the same dataset.
🔹 Ship via Platform early. Managed deploys + environment-scoped secrets make iteration safer and faster.
1️⃣ Goal: Marketing insights agent, fetch KPIs, summarize risks, draft an action plan, seek human sign-off.
2️⃣ Nodes: Planner → KPI_Tool → Writer → Reviewer → END.
3️⃣ Tools: get_kpis(account_id), search_trends(query).
4️⃣ Supervisor: If plan incomplete, Planner, if KPIs missing, KPI_Tool, if draft ready, Reviewer, if approved, END.
5️⃣ State: messages, plan, kpis, draft, approved, budgets.
6️⃣ Observability: One Langfuse trace per run, spans per node and per tool, experiment runner for prompt/model comparisons.
🔹 Repo ready (pyproject.toml/requirements.txt), langgraph config, CI for tests/lint.
🔹 Secrets set in platform (provider keys, DSNs).
🔹 Health route and sensible rate limits.
🔹 Tracing on by default, experiments pre-configured.
🔹 Shareable preview link for reviewers (or private workspace access).
✅ Start with a single tool-calling agent inside a LangGraph node and wire Langfuse tracing.
✅ Add a Supervisor and split responsibilities into small nodes, pass state via handoffs.
✅ Bake in evals/experiments before launch.
✅ Deploy on the LangGraph Platform with secrets and share a preview for fast feedback.